The iLCM is not a stand-alone software, but rather an infrastructure consisting of a multitude of components including a document database (MariaDB), an NLP pipeline for processing different text mining processes (In R statistical language), a full-text index (Solr) and a web application (R Shiny). To make the infrastructure available as a decentralized installation for other projects it is embedded in a virtual machine ensemble (Docker), which can be easily set up with predefined configuration scripts. The application is therefor a fusion of R scripting capabilities, Data Management and visualization by R Shiny. By using a ORC approach, the documentation of the data-processing happens on the fly, with always having the data, the used scripts and their description available in a “notebook” for later consideration.



Data Management
Corpora: The LCM allows managing multiple text corpora per user and also allows for sharing of corpora between users. Corpora are not closed at the time of their creation (import) but can be supplemented with additional documents at a later date. This allows the processing of continuous corpora, e.g. collections of newspaper articles, Wikipedia articles or social media data. In order to make the data import as easy as possible for users, import interfaces have been defined and implemented for XML, CSV, HTML, DOC, DOCX, RTF, PDF and plain text data. Furthermore, the Text Corpus Format (TCF) is supported (Heid et al., 2010).
Document Search: With a full-text search and metadata fields integrated into the LCM, documents can be filtered by keywords and metadata facets. A query language enables the complex combination of multiple search criteria, such as AND/OR combinations of search terms, the exclusion of certain terms, or the search for terms which must occur within a certain minimum distance from each other. Search result sets can be stored as individual collections which can serve as a basis for a refined search or for any further text mining analysis. Results from such analysis can then be aggregated with respect to the collection level. Moreover, each document can be displayed in a full-text view to allow for a close reading and qualitative checks of text mining results.
Analysis Features
Linguistic (pre-)processing: For most text miningapplications, text data must be transformed into a numeric representation. For instance, word counts per document over the entire vocabulary can be represented as a vector. All document vectors of a collection together form a document-term matrix (DTM) on which various text statistical evaluations can be processed. To generate such a DTM representation of a collection, we need several preprocessing capabilities. The LCM provides sentence segmentation, multi-word expression detection, POS-Tagging, Named Entity Tagging, Named Entity unification, lowercasing, stemming, lemmatization, stop word removal, ngram tokenization and data pruning which can be applied to the text data as needed. Additionally, the process chain for the linguistic preprocessing of documents is extended by syntactic parsing which is needed for an extended text analysis (e.g. subjectobject relationships). To fulfill those requirements we integrate the spaCy library. The open source Python library provides state of the art machine learning for natural language processing in multiple languages. Although spaCy is written in Python it can easily be integrated into the R environment with additional R packages.
Faceted Statistics: Result sets of search queries can be filtered with respect to certain indexed metadata. With this, a user can quickly generate a graphical representation of the document metadata for a search query or create time series for the search results. The occurrence of proper names in query related texts can also be displayed in an aggregated form which quickly allows for an overview of entities that can be identified with respect to a search query. Term Extraction/Keyword in Context: Lists of meaningful terms can be calculated by the aggregation of their probabilities in different topics produced by a topic model. Those terms can be used to characterize the content of large collections or for further steps such as the creation of dictionaries or the identification of candidates for individual term analyses. Furthermore, terms can be displayed as ”Keyword in Context” (KWIC).
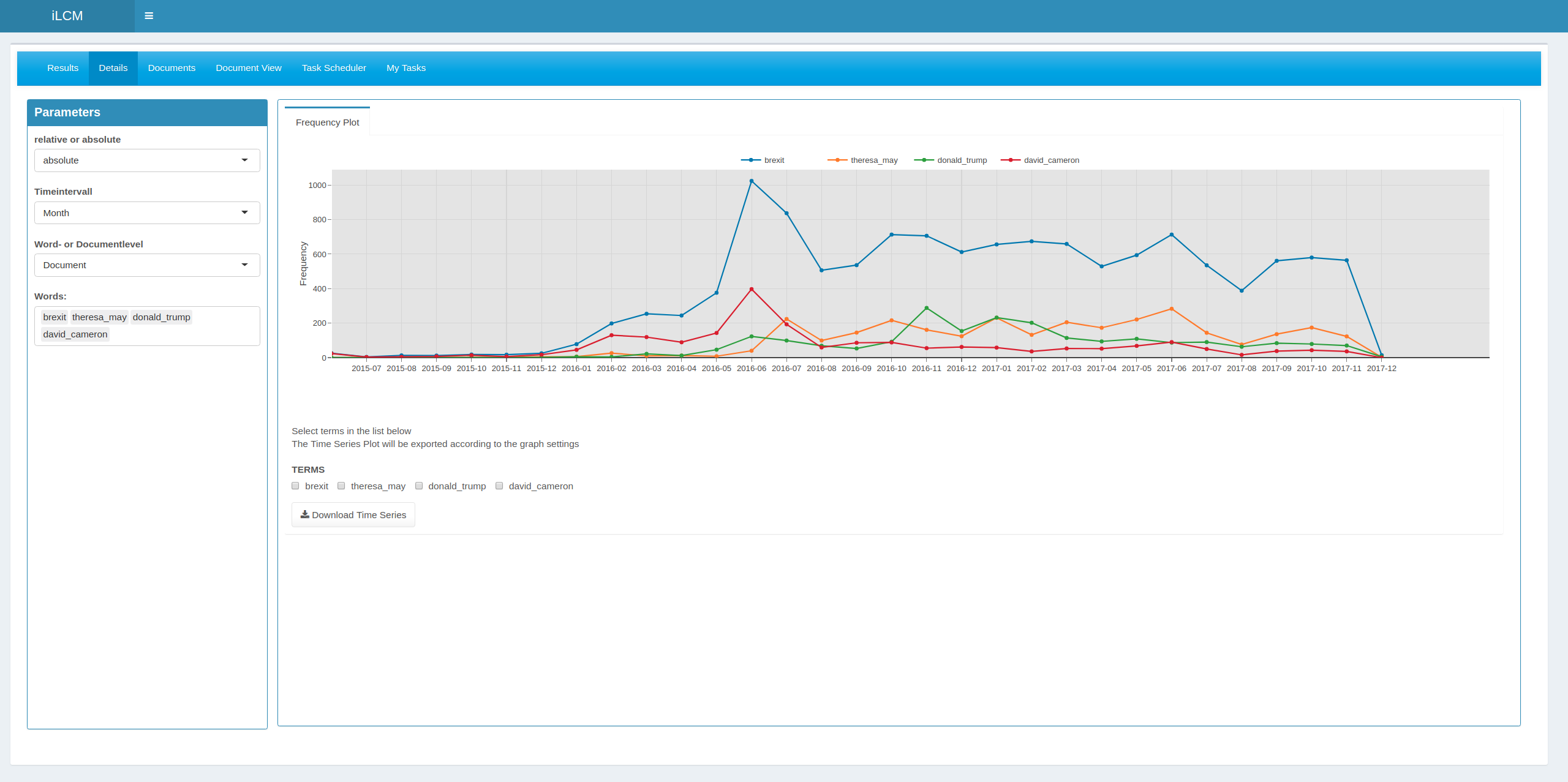
Word Frequencies/Dictionary Analysis: Similar to the measurement of document frequencies in relation to search results, the software provides possibilities for measuring term and document frequencies in document collections. According to the settings of a linguistic preprocessing chain, the articles in a collection are tokenized and the tokens are then counted, e.g. with reference to the publication dates of the articles. This allows the creation of time series for terms in absolute or normalized manner. Instead of single terms, also groups of terms representing semantically similar concepts, so-called dictionaries, can be used for frequency analysis.
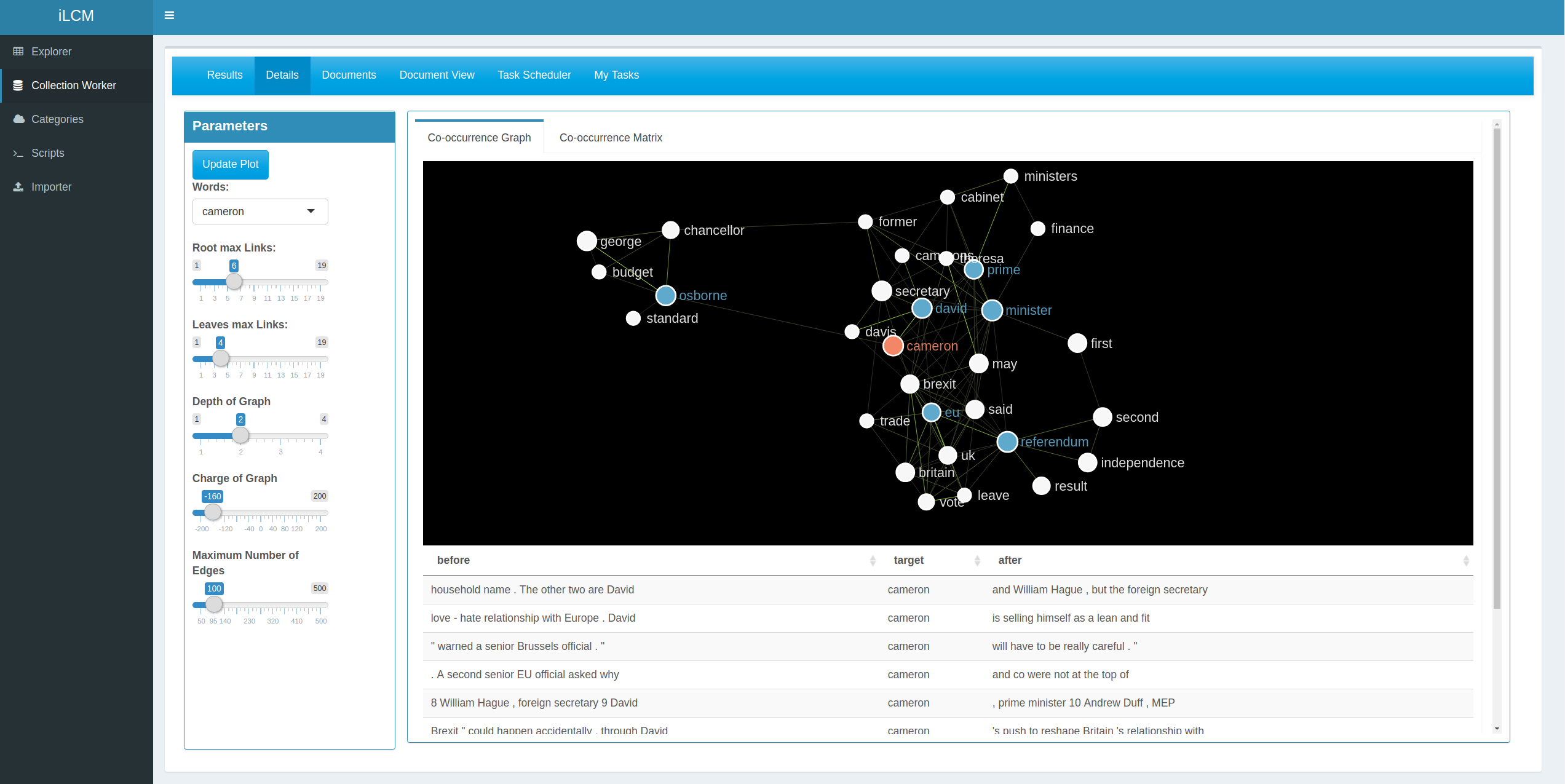
Co-occurrence Analysis: For the identification of semantic correlations, the statistical significance of word cooccurrences is decisive in addition to their frequency. We integrate several ways to compute the statistical significance of the co-occurrence of tokens within defined contextual units. Possible contextual units are sentences, paragraphs or documents. Furthermore, it is possible to extract co-occurrences from contextual windows (e.g. n-left and nright) and to analyse the ordering of the co-occurring words in the contextual units.
Context Volatility: Using the LCM enables researchers to deal with diachronic text data. The amount of contextual change for certain words over a period of time can be analyzed using a measure which captures this property. In the LCM several settings of measuring context change along with state of the art visualizations for the results are be implemented.
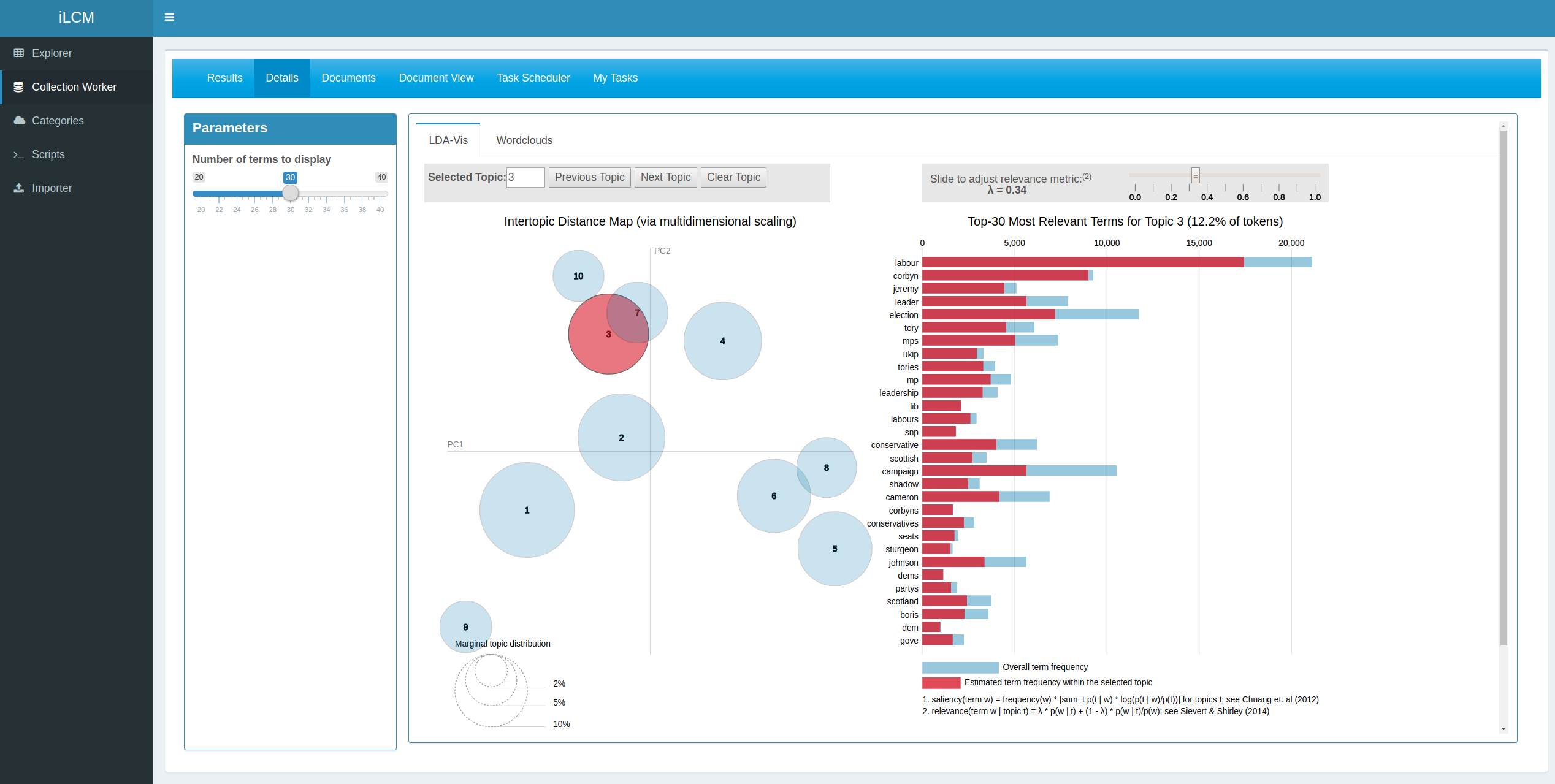
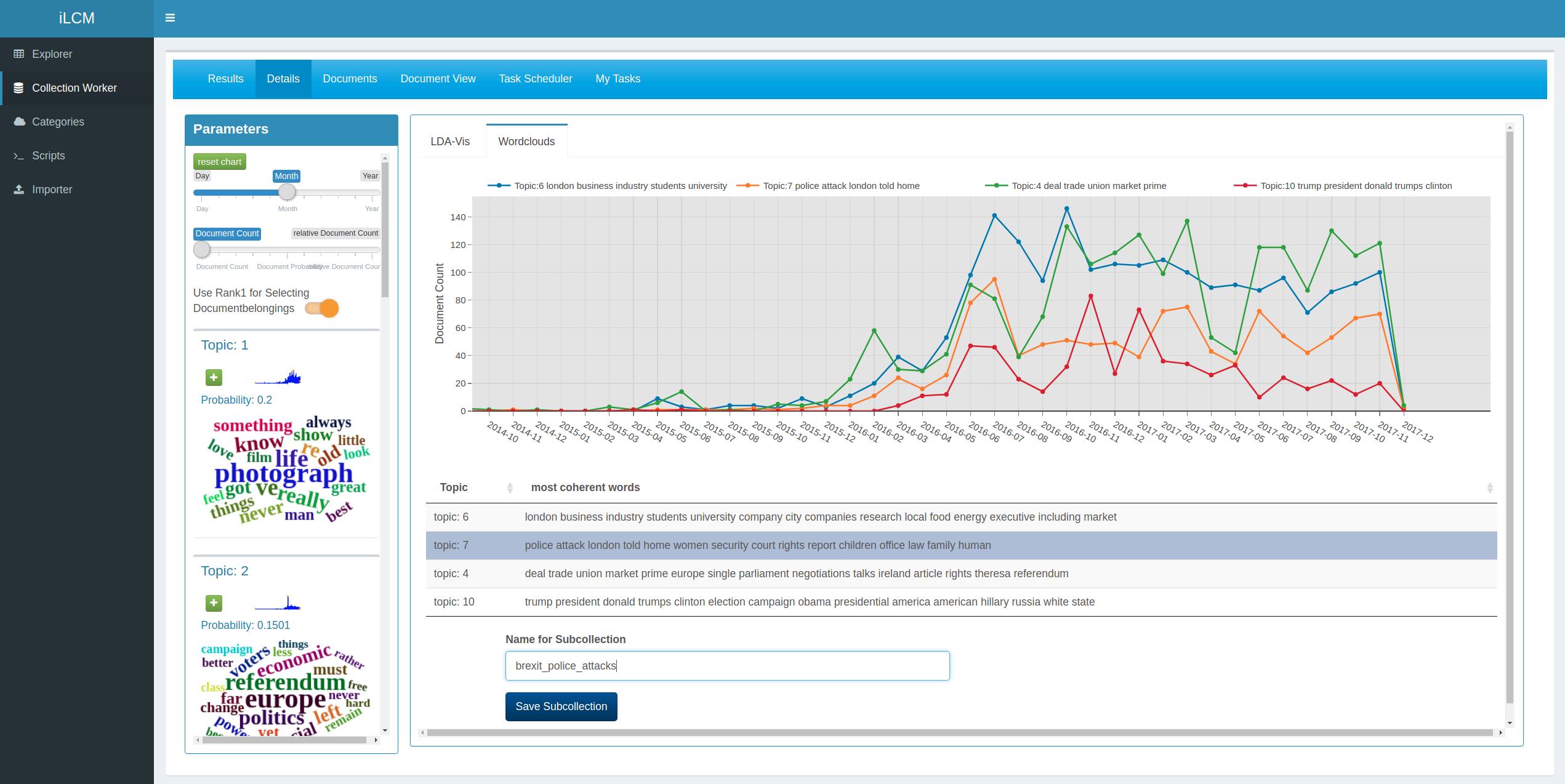
Topic Models: Topic models are probabilistic models that attempt to infer semantic clusters (which can be interpreted as topics) in document collections. As a result, topic models provide probability distributions over the set of all words for each topic. Furthermore, they provide probability distributions over the set of topics for each document. A topic can be semantically interpreted using the n most probable words it contains. For this purpose, the software provides sorted term lists for each calculated topic as well as an integration of the topic model result browser LDAvis. We further add functionality to determine optimal hyperparameters for the modeling process and to measure its reliability over repeated runs.
Manual Annotation: Manual methods of qualitative data analysis usually work with categories. Those could be obtained inductively from the empirical material through reading and interpretation. More importantly, categories can be deductively guided and operationalized on the basis of existing theories (e.g. with the help of lists of terms, so-called dictionaries). This is supported by the definition of hierarchical category systems, encoding of entire documents or text segments with categories of the category system, measurement of intercoder matches and administration and export of the manually coded data. Due to the browser-based user interface, several annotators can simultaneously work on the same document set with a shared category system.
Supervised Classification: Categories for which a high intercoder reliability can be achieved, i.e. which are defined sufficiently unambiguously so that different encoders assign (mostly) the same categories for documents or passages of text, are also suitable for automatic classification procedures. Supervised methods for classification use given training examples to learn how to classify a data object into a defined class or category. Accordingly, the LCM offers the possibility of accepting text passages assigned to category X as positive training examples. Text passages in annotated documents that are not coded with X become negative training examples. A machine classifier learns textual features (especially word occurrences and their combinations) which suggest the existence of a certain class. This allows for an active learning scenario, where new text passages fitting to a certain category are identified within a collection automatically (Wiedemann, 2018). In an iterated process, automatic suggestions can be corrected by a human annotator to improve the classification model. In addition to text (passage) categorization, we further provide functionality for sequence classification to allow for complex information extraction.
Combination of individual procedures: The individual procedures already allow for interesting analysis of large text collections. But, in a CSS scenario, most benefit is to be expected from combined applications of the analysis modules in complex workflows. For instance, a topic model result is useful for interpretation in itself already. However, for content analysis, it is also interesting to use the topic model result as a filter for the original document collection. The result could be used to split a heterogeneous collection into thematically coherent sub-collections. These filtered sub-collections can be analyzed further as time series on the prominence of a theme. Also, further analysis procedures such as dictionary analysis could be applied to test hypotheses with respect to certain topics. In another scenario, frequency observations over time can be used to identify periods that indicate a similar use of terms and points in time at which changes occur (e.g. peaks in time curves). These periods of time can be used to divide a collection into distinct sub-collections on which further comparative analyses such as co-occurrence analysis can be applied. In summary, the LCM allows for various combinations of the provided modules in creative ways which fit the research requirements of the end-users. Information about the source collection, the selected analysis process and corresponding parameters for each analysis result are logged by the system in a way that allows for documentation of the conducted research.
tmca (Text Mining for Content Analysis) for R
The LCM is based on a library providing basic processing abstractions for text mining. Especially the application of text mining to social science content analysis is reflected in this library. The library is a basically a wrapper around quanteda, R spaCy, lda, liblineaR and many more in order to provide a convenient and methodologically sound access to those tools. The reprository can be found here:
https://git.informatik.uni-leipzig.de/gwiedemann/R_tmca_package
ShinyLCM
The visual access to the toolsets of the tmca package are integrated into a R Shiny App. The visual component, the TMCA package and storage capabilities (Docker, Solr, Maria DB) for the LCM service architecture.
https://git.informatik.uni-leipzig.de/mam10cip/iLCM-ShinyApp